
One of many essential points that has been introduced up over the course of the Olympic stress-net launch is the massive quantity of information that purchasers are required to retailer; over little greater than three months of operation, and notably over the past month, the quantity of information in every Ethereum consumer’s blockchain folder has ballooned to a powerful 10-40 gigabytes, relying on which consumer you’re utilizing and whether or not or not compression is enabled. Though you will need to notice that that is certainly a stress take a look at situation the place customers are incentivized to dump transactions on the blockchain paying solely the free test-ether as a transaction price, and transaction throughput ranges are thus a number of occasions increased than Bitcoin, it’s nonetheless a respectable concern for customers, who in lots of circumstances don’t have tons of of gigabytes to spare on storing different individuals’s transaction histories.
To begin with, allow us to start by exploring why the present Ethereum consumer database is so giant. Ethereum, in contrast to Bitcoin, has the property that each block accommodates one thing known as the “state root”: the foundation hash of a specialized kind of Merkle tree which shops the complete state of the system: all account balances, contract storage, contract code and account nonces are inside.
The aim of that is easy: it permits a node given solely the final block, along with some assurance that the final block really is the latest block, to “synchronize” with the blockchain extraordinarily rapidly with out processing any historic transactions, by merely downloading the remainder of the tree from nodes within the community (the proposed HashLookup wire protocol message will faciliate this), verifying that the tree is appropriate by checking that all the hashes match up, after which continuing from there. In a completely decentralized context, it will probably be executed via a sophisticated model of Bitcoin’s headers-first-verification technique, which is able to look roughly as follows:
- Obtain as many block headers because the consumer can get its fingers on.
- Decide the header which is on the tip of the longest chain. Ranging from that header, return 100 blocks for security, and name the block at that place P100(H) (“the hundredth-generation grandparent of the top”)
- Obtain the state tree from the state root of P100(H), utilizing the HashLookup opcode (notice that after the primary one or two rounds, this may be parallelized amongst as many friends as desired). Confirm that each one components of the tree match up.
- Proceed usually from there.
For mild purchasers, the state root is much more advantageous: they’ll instantly decide the precise steadiness and standing of any account by merely asking the community for a specific department of the tree, with no need to observe Bitcoin’s multi-step 1-of-N “ask for all transaction outputs, then ask for all transactions spending these outputs, and take the rest” light-client mannequin.
Nevertheless, this state tree mechanism has an essential drawback if carried out naively: the intermediate nodes within the tree enormously improve the quantity of disk area required to retailer all the information. To see why, take into account this diagram right here:
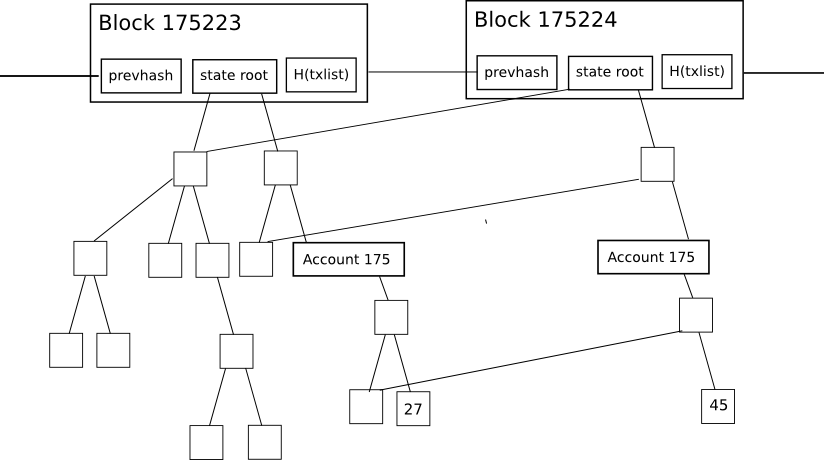
The change within the tree throughout every particular person block is pretty small, and the magic of the tree as an information construction is that a lot of the information can merely be referenced twice with out being copied. Nevertheless, even nonetheless, for each change to the state that’s made, a logarithmically giant variety of nodes (ie. ~5 at 1000 nodes, ~10 at 1000000 nodes, ~15 at 1000000000 nodes) have to be saved twice, one model for the previous tree and one model for the brand new trie. Finally, as a node processes each block, we are able to thus anticipate the overall disk area utilization to be, in laptop science phrases, roughly O(n*log(n)), the place n is the transaction load. In sensible phrases, the Ethereum blockchain is just one.3 gigabytes, however the dimension of the database together with all these additional nodes is 10-40 gigabytes.
So, what can we do? One backward-looking repair is to easily go forward and implement headers-first syncing, primarily resetting new customers’ onerous disk consumption to zero, and permitting customers to maintain their onerous disk consumption low by re-syncing each one or two months, however that could be a considerably ugly resolution. The choice method is to implement state tree pruning: primarily, use reference counting to trace when nodes within the tree (right here utilizing “node” within the computer-science time period that means “piece of information that’s someplace in a graph or tree construction”, not “laptop on the community”) drop out of the tree, and at that time put them on “demise row”: except the node in some way turns into used once more throughout the subsequent X blocks (eg. X = 5000), after that variety of blocks go the node must be completely deleted from the database. Basically, we retailer the tree nodes which are half of the present state, and we even retailer latest historical past, however we don’t retailer historical past older than 5000 blocks.
X must be set as little as potential to preserve area, however setting X too low compromises robustness: as soon as this system is carried out, a node can not revert again greater than X blocks with out primarily fully restarting synchronization. Now, let’s examine how this method may be carried out totally, considering all the nook circumstances:
- When processing a block with quantity N, preserve monitor of all nodes (within the state, tree and receipt timber) whose reference depend drops to zero. Place the hashes of those nodes right into a “demise row” database in some type of information construction in order that the record can later be recalled by block quantity (particularly, block quantity N + X), and mark the node database entry itself as being deletion-worthy at block N + X.
- If a node that’s on demise row will get re-instated (a sensible instance of that is account A buying some specific steadiness/nonce/code/storage mixture f, then switching to a unique worth g, after which account B buying state f whereas the node for f is on demise row), then improve its reference depend again to at least one. If that node is deleted once more at some future block M (with M > N), then put it again on the long run block’s demise row to be deleted at block M + X.
- Once you get to processing block N + X, recall the record of hashes that you just logged again throughout block N. Examine the node related to every hash; if the node continues to be marked for deletion throughout that particular block (ie. not reinstated, and importantly not reinstated after which re-marked for deletion later), delete it. Delete the record of hashes within the demise row database as effectively.
- Generally, the brand new head of a series is not going to be on high of the earlier head and you will have to revert a block. For these circumstances, you will have to maintain within the database a journal of all adjustments to reference counts (that is “journal” as in journaling file systems; primarily an ordered record of the adjustments made); when reverting a block, delete the demise row record generated when producing that block, and undo the adjustments made based on the journal (and delete the journal once you’re executed).
- When processing a block, delete the journal at block N – X; you aren’t able to reverting greater than X blocks anyway, so the journal is superfluous (and, if stored, would in truth defeat the entire level of pruning).
As soon as that is executed, the database ought to solely be storing state nodes related to the final X blocks, so you’ll nonetheless have all the knowledge you want from these blocks however nothing extra. On high of this, there are additional optimizations. Notably, after X blocks, transaction and receipt timber must be deleted fully, and even blocks might arguably be deleted as effectively – though there is a vital argument for holding some subset of “archive nodes” that retailer completely every part in order to assist the remainder of the community purchase the information that it wants.
Now, how a lot financial savings can this give us? Because it seems, quite a bit! Notably, if we had been to take the last word daredevil route and go X = 0 (ie. lose completely all capability to deal with even single-block forks, storing no historical past by any means), then the scale of the database would primarily be the scale of the state: a price which, even now (this information was grabbed at block 670000) stands at roughly 40 megabytes – the vast majority of which is made up of accounts like this one with storage slots crammed to intentionally spam the community. At X = 100000, we’d get primarily the present dimension of 10-40 gigabytes, as a lot of the progress occurred within the final hundred thousand blocks, and the additional area required for storing journals and demise row lists would make up the remainder of the distinction. At each worth in between, we are able to anticipate the disk area progress to be linear (ie. X = 10000 would take us about ninety p.c of the best way there to near-zero).
Word that we might wish to pursue a hybrid technique: holding each block however not each state tree node; on this case, we would wish so as to add roughly 1.4 gigabytes to retailer the block information. It is essential to notice that the reason for the blockchain dimension is NOT quick block occasions; at the moment, the block headers of the final three months make up roughly 300 megabytes, and the remainder is transactions of the final one month, so at excessive ranges of utilization we are able to anticipate to proceed to see transactions dominate. That stated, mild purchasers may also must prune block headers if they’re to outlive in low-memory circumstances.
The technique described above has been carried out in a really early alpha kind in pyeth; will probably be carried out correctly in all purchasers in due time after Frontier launches, as such storage bloat is just a medium-term and never a short-term scalability concern.